{
"cells": [
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Chapter 2: 2.1-2.8: Syntax and data types\n",
"\n",
"The material presented in this notebook will be based off of Chapter 2 of the DeCaria Textbook. Some topics that will be covered include:\n",
"- The basics surround Python syntax \n",
"- Assigning variable names\n",
"- An introduction to different Python data types\n",
"\n",
"**Before starting:** Make sure that you open up a Jupyter notebook session using OnDemand so you can interactively follow along with today's lecture! If you have forgotten how to do this, refer to the previous lecture and class notes. Also, be sure to copy this script into your atmos5340/module_3 subdirectory!\n",
"\n",
"
"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"**Syntax note**: Python is case-sensitive! PRESSURE, pressure, and Pressure are *NOT* the same variables. Similarly, this also applies to functions as well. For example, the function print() will print out the value assigned to a variable, while Print() would result in an error, unless the user defined their own function named 'Print'."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#This will work...\n",
"a = 1\n",
"print(a)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#This will NOT work...\n",
"Print(a)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"**Syntax note**: Comments can be added to your code using the **#** symbol. Comments are useful for describing the code that is written, and it will help others interpret the logic behind the code that you have written. There is nothing worse then trying to read someone's code (or perhaps even your own!) and not understanding the logic that went behind a specific line of code! The *#* should be used before any characters that you do not want the Python interpreter to read."
]
},
{
"cell_type": "code",
"execution_count": 1,
"metadata": {},
"outputs": [],
"source": [
"#This this ok\n",
"a = 2"
]
},
{
"cell_type": "code",
"execution_count": 2,
"metadata": {},
"outputs": [],
"source": [
"a = 2 #this is ok"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"a = 2 not ok #"
]
},
{
"cell_type": "code",
"execution_count": 3,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"1\n"
]
}
],
"source": [
"#This block of code will be used to print out\n",
"#the number assigned to variable a.\n",
"a = 1\n",
"print(a)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"**Going back to the** *print* **function:** This is a useful command for print out the values of variables to the command line. This is particularly useful when debugging code!\n",
"
"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"
\n",
"**Function:** A function is a command that allows python (or any other programming) to peform an automated task, which internally consists of a number of Python commands (under the hood). For example, the function np.mean() will compute the mean of values assigned to the function. The assignment of values to a function is referred to as an 'argument'. Users can also define their own arguments if there is a particular, repeatable task that needs to be carried out. A deeper analysis on 'functions' will be presented in **Chapter 8** of the DeCaria text."
]
},
{
"cell_type": "code",
"execution_count": 4,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"3.0\n"
]
}
],
"source": [
"#Example of a function being used\n",
"import numpy as np\n",
"\n",
"values = [1,2,3,4,5]\n",
"mean_val = np.mean(values)\n",
"print(mean_val)\n",
" "
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"**What are we doing here?**\n",
"- The first line of code *'import numpy as np'* is importing the NumPy library so we can take advantage of NumPy's numeric functions such as NumPy mean. We short-hand *numpy* as *np*. \n",
"- The second line of code is then assigning a list of numbers from 1-5 to a variable called *values* \n",
"- The third line of code is then taking the average of this list of numbers using the np.mean function.\n",
"- The fourth lines prints out the average value assigned to *mean_val*\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"
\n",
"**Code blocks and indentations:** While Python is considered a free-form language, and does have structure in that it uses indentations to delineate code blocks. This is useful in that it forces the user to properly indent their code, which generally makes a piece of code much more readable! Even in the absense of this requirement, all programmers should be indenting their code when appropriate as it makes it easier for a user to follow the logic of the code.\n",
"\n",
"An example of this can be seen in the following for loop, which loops through each value between 0 and 5, and performs a command, and prints out a value depending on the index that we are on (0-5):"
]
},
{
"cell_type": "code",
"execution_count": 5,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"0\n",
"1\n",
"4\n",
"9\n",
"16\n"
]
}
],
"source": [
"for i in range(0,5):\n",
" i = i **2\n",
" print(i)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"All loops in Python require a colon (:), which tells Python that it is about to execute a code block, like in the example above. Note, that while the indentation requirement is nice as it forces users to delineate their code appropriately, it can be difficult to copy-paste this code into the command line as tabs are sometimes not appropriately interpreted by the Python command line. With Jupyter notebook, this is not nearly as problematic. \n",
"
"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"
\n",
"**Continuation of lines:** Python does not have a line length limit like older programming languages like Fortran 77. However, it is recommended that longer lines are broken up to make the code more readable. To break up long lines of code, a '\\' is used to signify that the following line is a continuation:"
]
},
{
"cell_type": "code",
"execution_count": 6,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"My favorite type of cloud in the sky is a cumulonimbus\n"
]
}
],
"source": [
"x = 'My favorite type of cloud in the sky is a cumulonimbus'\n",
"print(x)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"or"
]
},
{
"cell_type": "code",
"execution_count": 7,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"My favorite type of cloudin the sky is a cumulonimbus\n"
]
}
],
"source": [
"x = 'My favorite type of cloud' \\\n",
" 'in the sky is a cumulonimbus' \n",
"print(x)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"There are also several scenerios where a \\ is not necessary. For example, comma-seperated elements contained within a paranthesis (), bracket [], or curly brackets {} can be continued on a different line without using a back slash, for example:"
]
},
{
"cell_type": "code",
"execution_count": 8,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"hello my name is john\n"
]
}
],
"source": [
"print('hello','my','name','is','john')"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"is the same as:"
]
},
{
"cell_type": "code",
"execution_count": 9,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"hello my name is john\n"
]
}
],
"source": [
"print('hello','my','name',\n",
"'is','john')"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"
\n",
"**Assigning variable names:** Letters and numbers can be used when naming a variable. Limitations include:\n",
"> Numbers can't be used as the first character when naming a variable
\n",
"> Leading underscores are not recommended
\n",
"> Avoid using the reserved words as discussed in the **DeCaria text in Section 2.2.2**
\n",
"
"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Assigning a value to a variable can be accomplished using the assignment operator '='. For example:"
]
},
{
"cell_type": "code",
"execution_count": 10,
"metadata": {},
"outputs": [],
"source": [
"a = 3.14"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Here a floating-point value of 3.14 has been assigned to a. Characters can also be assigned to variables:"
]
},
{
"cell_type": "code",
"execution_count": 11,
"metadata": {},
"outputs": [],
"source": [
"b = 'hello'"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"
\n",
"**Numeric data types:** There are four numeric types used by Python. These include booleans, integers, floating-points, and complex numbers. Booleans are designated by 'True' or 'False':"
]
},
{
"cell_type": "code",
"execution_count": 12,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"1.0\n",
"0.0\n"
]
}
],
"source": [
"boo = True\n",
"print(float(boo))\n",
"boo = False\n",
"print(float(boo))\n",
" "
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Integers is a variable that is an integer and is often used to index Python arrays. "
]
},
{
"cell_type": "code",
"execution_count": 13,
"metadata": {},
"outputs": [],
"source": [
"a = 3"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Floating-point values are different from integers in that they are stored as 64 bits or the equivalent of double precision. These variables can be expressed as decimals or using scientific notation:"
]
},
{
"cell_type": "code",
"execution_count": 36,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"0.0065\n"
]
}
],
"source": [
"a = 4.1\n",
"b = 4.6e9\n",
"c = -7.3e3\n",
"d = 6.5e-3\n",
"print(d)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
" It is worth noting that it is also possible to convert between numeric data types. For example you can convert a floating number into an integer:"
]
},
{
"cell_type": "code",
"execution_count": 15,
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"int"
]
},
"execution_count": 15,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"val = 4\n",
"type(val)"
]
},
{
"cell_type": "code",
"execution_count": 16,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"4.0\n"
]
}
],
"source": [
"val = float(val)\n",
"print(val)"
]
},
{
"cell_type": "code",
"execution_count": 17,
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"float"
]
},
"execution_count": 17,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"type(val)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Speaking of data types, the 'type' function can be used to determine the data type as seen above, and not just for numeric data types for that matter.\n",
"
\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"
\n",
"**Attributes and methods:** Python variables/objects may also have attributes assigned to them. For example, a complex number may have an attribute named real, which is the real part of the complex number. The other attribute of a complex number is its imaginary part 'imag':"
]
},
{
"cell_type": "code",
"execution_count": 18,
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"-3.2"
]
},
"execution_count": 18,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"complex = 4.5 - 3.2j\n",
"complex.imag"
]
},
{
"cell_type": "code",
"execution_count": 19,
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"4.5"
]
},
"execution_count": 19,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"complex.real"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"**Methods** can also be associated with variables. A method is analogous to function that belongs to a variable/object. We will see more examples of methods later in this course. "
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"**Strings:** Strings are assigned to a variable using single or double quotations. This will be more thoroughly discussed in the next following Chapter and class lecture. "
]
},
{
"cell_type": "code",
"execution_count": 20,
"metadata": {},
"outputs": [],
"source": [
"my_string = 'hello'\n",
"num_string = '456.3'"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"
\n",
"**Lists and tuples:** These variable types are essentially collection of values. The major differences between lists and tuples is that lists are mutable, which means that their contents can be changed after being created. Tuples are immutable, thus cannot be changed after being created. These variables are assigned using square brackets or parentheses. "
]
},
{
"cell_type": "code",
"execution_count": 37,
"metadata": {},
"outputs": [],
"source": [
"my_list = [4.5,-7.8,'pickle',5,1e7,True] #List\n",
"my_tupl = (4.5,-7.8,'pickle',5,1e7,True) #Tuple"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Lists and tuples can also be indexed to pull out individual elements or values within a list or tuple. "
]
},
{
"cell_type": "code",
"execution_count": 38,
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"4.5"
]
},
"execution_count": 38,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"my_list[0]"
]
},
{
"cell_type": "code",
"execution_count": 39,
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"'pickle'"
]
},
"execution_count": 39,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"my_list[2]"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"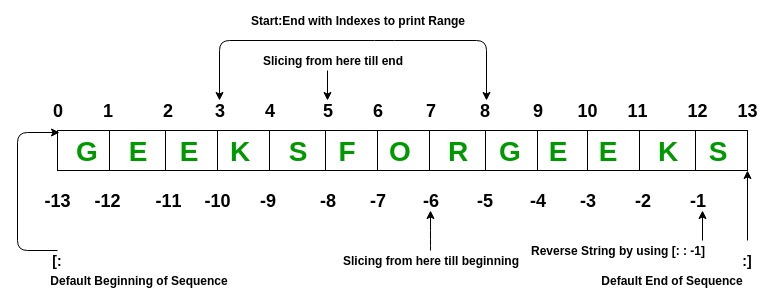 \n",
"\n",
"Note that Python's indexing scheme is 0 based in that 0 represents the first element in a 1-D list/tuple/array.
\n",
"\n",
"Note that Python's indexing scheme is 0 based in that 0 represents the first element in a 1-D list/tuple/array.
\n",
"Some other tricks with Python indexing: -1 can be used to return the last element in a list/tuple/array."
]
},
{
"cell_type": "code",
"execution_count": 40,
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"True"
]
},
"execution_count": 40,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"my_list[-1]"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"In a somewhat longer way, you could also use Python's length command to grab the last element in a list/tuple/array. "
]
},
{
"cell_type": "code",
"execution_count": 24,
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"True"
]
},
"execution_count": 24,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"my_list[len(my_list)-1]"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"You can also subset a list/tuple/array by choosing an index range using a colon:"
]
},
{
"cell_type": "code",
"execution_count": 47,
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"[-7.8, 'pickle', 5, 10000000.0]"
]
},
"execution_count": 47,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"my_list = [4.5,-7.8,'pickle',5,1e7,True] #List\n",
"my_list[1:5] "
]
},
{
"cell_type": "code",
"execution_count": 48,
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"[4.5, 'pickle', 10000000.0]"
]
},
"execution_count": 48,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"my_list[0:len(my_list):2] "
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Indexing can also be used to reassign a value within a list:"
]
},
{
"cell_type": "code",
"execution_count": 49,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"[4.5, -7.8, 14, 5, 10000000.0, True]\n"
]
}
],
"source": [
"my_list[2] = 14\n",
"print(my_list)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Finally, if you accidently assign an index that is outside of indices within a array, Python will spit back the following error:"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"my_list[10]"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Many more examples and details on subsetting list/tuple/arrays can be reviewed in **Section 2.7** in the DeCaria text.\n",
"
\n",
"Instead of manually defining a range of numbers, the 'range' function in Python can be used to create a sequence of integers. The arguements for the range function include the starting value, ending value, and the stride: range(start,end,stride)"
]
},
{
"cell_type": "code",
"execution_count": 28,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"[0, 2, 4, 6, 8]\n"
]
}
],
"source": [
"my_list = list(range(0,10,2))\n",
"print(my_list)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"If no stride is included, the range function defaults to using a stride of 1."
]
},
{
"cell_type": "code",
"execution_count": 29,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]\n"
]
}
],
"source": [
"my_list = list(range(0,10))\n",
"print(my_list)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"
\n",
" **Some useful functions when working with lists...***"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
" > len(my_list) #computes length of a list\n",
" > del my_list[i:j] #deletes values at the i through j index\n",
" > my_list.append(element) #adds an element to the end of an existing list\n",
" > my_list.extend(another_list). #adds values from another list to an existing list\n",
" > my_list.count(target) #counts instances of target variable in our list\n",
" > my_list.reverse #reverse our list"
]
},
{
"cell_type": "code",
"execution_count": 30,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]\n"
]
}
],
"source": [
"print(my_list)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"More useful functions can be found in **Section 2.7** in the DeCaria text.\n",
"
"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"
\n",
"**Dictionaries:** A dictionary is similar to a list with the exception that instead of indexing with integers, a dictionary uses a key number, string, or another object. "
]
},
{
"cell_type": "code",
"execution_count": 31,
"metadata": {},
"outputs": [],
"source": [
"thisdict = {\"brand\": \"Ford\",\"model\": \"Mustang\",\"year\": 1964}"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"One of the 'keys' in this case is model:"
]
},
{
"cell_type": "code",
"execution_count": 32,
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"'Mustang'"
]
},
"execution_count": 32,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"thisdict[\"model\"]"
]
},
{
"cell_type": "code",
"execution_count": 33,
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"1964"
]
},
"execution_count": 33,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"thisdict[\"year\"]"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
" which will retrieve the cars 'model'?\n",
" \n",
"Another example: \n"
]
},
{
"cell_type": "code",
"execution_count": 34,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"dict_keys([1, 2, 3])\n",
"b\n"
]
}
],
"source": [
"my_dictionary = {1:'b', \\\n",
" 2: [23,265,12,43], \\\n",
" 3: ('this', 'is', 'a', 'tuple')}\n",
"\n",
"print(my_dictionary.keys())\n",
"print(my_dictionary[1])"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"More examples..."
]
},
{
"cell_type": "code",
"execution_count": 35,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"dict_keys(['name', 'school', 'hours in office'])\n",
"Derek\n",
"D\n",
"[8, 9, 10, 11, 12, 13, 14, 15]\n",
"\n"
]
}
],
"source": [
"another_dictionary = {'name':'Derek', \\\n",
" 'school': 'university of utah', \\\n",
" 'hours in office': [8, 9, 10, 11, 12, 13, 14, 15]}\n",
"\n",
"print(another_dictionary.keys())\n",
"print(another_dictionary['name'])\n",
"print(another_dictionary['name'][0])\n",
"print(another_dictionary['hours in office'])\n",
"\n",
"print(type(another_dictionary))"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"
\n",
"---\n",
"---\n",
"\n",
"> # Want more practice!\n",
"> Try this tutorial...https://www.tutorialspoint.com/python3/index.htm. \n",
">\n",
"> Or try the [Codecademy Python course](https://www.codecademy.com/learn/learn-python). The course for version 2 is free . The version 3 course requires a subscription, but that isn't necessary since python 2 and 3 are so similar. Just be aware of the difference: \n",
">\n",
"> Another resource: https://www.datacamp.com/courses/intro-to-python-for-data-science"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": []
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": []
}
],
"metadata": {
"kernelspec": {
"display_name": "Python 3 (ipykernel)",
"language": "python",
"name": "python3"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.10.5"
},
"widgets": {
"application/vnd.jupyter.widget-state+json": {
"state": {},
"version_major": 2,
"version_minor": 0
}
}
},
"nbformat": 4,
"nbformat_minor": 4
}