{
"cells": [
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Module 8: Python Pandas\n",
"## Chapter 15 & 16 from the Alex DeCaria textbook\n",
"\n",
"Pandas is a data manipulation tool built on Python's Numpy module. Pandas introduces two new data type structures. The first data structure type is a Pandas *series*, which is a one dimensional array. The second data structure is a *'dataframe'*, which is similar to a 2-D NumPy array, except that it can hold multiple data types within it (strings, floats, integers, datetime objects, ect...). This features make Pandas particularly good for working with time series data. In addition, I've always found reading in text and csv data rather annoying in Python, but Pandas makes this task MUCH easier! For today, we will: \n",
"- Read csv-formatted data into Python \n",
"- Learn how to subset and slice dataframes \n",
"- Aggegrate and group data\n",
"- Work with time objects in Pandas\n",
"- While not discussed here, plotting data from a Pandas dataframe is super easy! (We will learn about Python plotting next week)\n",
"\n",
"**Before starting:** Make sure that you open up a Jupyter notebook session using OnDemand so you can interactively follow along with today's lecture! Also be sure to copy this Jupyter Notebook files as instructed on CANVAS!\n",
"\n",
" "
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"
\n",
"\n",
"# Reading in data\n",
"\n",
"As a starting point, lets load the appriopriate libraries for working with Pandas:"
]
},
{
"cell_type": "code",
"execution_count": 1,
"metadata": {},
"outputs": [],
"source": [
"import numpy as np\n",
"import pandas as pd"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"For the purpose of this class, we will mostly be working with *dataframes* as we will mostly be working with 2D data sets. As a first step, lets fire up a linux terminal session and copy the filed called:
\n",
"*module8_WBB.csv*
\n",
"*module8_zoo.csv*
\n",
"These can be found in:
\n",
"*/uufs/chpc.utah.edu/common/home/u0703457/public_html/dereks_homepage/Atmos_5340/module_8*
\n",
"
\n",
"Copy this file into your working directory (preferably, in the same directory as this script, which you have hopefully downloaded and placed in your module8 subdirectory.\n",
"
\n",
"⚠️⚠️⚠️ *As a sanity check lets look at this file using the 'more' command in linux to check out the contents of these files, and to ensure that we are looking at the correct file. You should **ALWAYS** look at the files you plan on reading in with any programming language to make sure the contents are what you think they are*\n",
"
\n",
"To read in a csv file, we will be using the `pd.read_csv()` function, which is similar to Python's default csv function, except that it is a bit less cumbersome to use! This function has a number of arguments that will allow this code to deal all sorts of csv files. For this lecture, we will just focus on a few key arguments:\n",
"\n",
">- `filepath_or_buffer`: name of file we are reading in\n",
">- `sep`: how are values seperated in our csv file\n",
">- `header`: Do we want to include our header? If left as blank, column names are assigned from the first row of our csv file.\n",
">- `skiprows`: How many rows do we want to skip when reading in our file? (0-base index).\n",
"\n",
"
\n",
"Other arguments for this function can be found here: https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.read_csv.html\n",
"
\n",
"Lets read in our file now:\n"
]
},
{
"cell_type": "code",
"execution_count": 2,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
" animal uniq_id water_need\n",
"0 elephant 1001 500\n",
"1 elephant 1002 600\n",
"2 elephant 1003 550\n",
"3 tiger 1004 300\n",
"4 tiger 1005 320\n",
"5 tiger 1006 330\n",
"6 tiger 1007 290\n",
"7 tiger 1008 310\n",
"8 zebra 1009 200\n",
"9 zebra 1010 220\n",
"10 zebra 1011 240\n",
"11 zebra 1012 230\n",
"12 zebra 1013 220\n",
"13 zebra 1014 100\n",
"14 zebra 1015 80\n",
"15 lion 1016 420\n",
"16 lion 1017 600\n",
"17 lion 1018 500\n",
"18 lion 1019 390\n",
"19 kangaroo 1020 410\n",
"20 kangaroo 1021 430\n",
"21 kangaroo 1022 410\n"
]
}
],
"source": [
"my_zoo = pd.read_csv('module8_zoo.csv', delimiter = ',')\n",
"print(my_zoo)"
]
},
{
"cell_type": "code",
"execution_count": 3,
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"pandas.core.frame.DataFrame"
]
},
"execution_count": 3,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"type(my_zoo)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"And that is it..! Reading in data with Pandas is usually very easy, especially when its a nicely formatted csv file! As seen in our print statement, we are working with a Pandas data frame, where the indices on the left are the index numbers of our 2D array, while the column names are defined using the column names from the first row of our csv file."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"
\n",
"\n",
"# Selecting rows and columns\n",
"\n",
"Selecting a specific row or column within a Pandas dataframe is fairly simple. To index a column, we just use the dataframe variable name, and subset the columns by using the name of the column that we would like to select:"
]
},
{
"cell_type": "code",
"execution_count": 4,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"0 elephant\n",
"1 elephant\n",
"2 elephant\n",
"3 tiger\n",
"4 tiger\n",
"5 tiger\n",
"6 tiger\n",
"7 tiger\n",
"8 zebra\n",
"9 zebra\n",
"10 zebra\n",
"11 zebra\n",
"12 zebra\n",
"13 zebra\n",
"14 zebra\n",
"15 lion\n",
"16 lion\n",
"17 lion\n",
"18 lion\n",
"19 kangaroo\n",
"20 kangaroo\n",
"21 kangaroo\n",
"Name: animal, dtype: object\n"
]
}
],
"source": [
"print(my_zoo['animal'])"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"
\n",
"\n",
"To get the first 5 rows of our dataframe, we can slice our data frame with the following command:"
]
},
{
"cell_type": "code",
"execution_count": 5,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
" animal uniq_id water_need\n",
"0 elephant 1001 500\n",
"1 elephant 1002 600\n",
"2 elephant 1003 550\n"
]
}
],
"source": [
"print(my_zoo[:3])"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"
\n",
"\n",
"We can also combine both commands to subset our data from the first 3 rows of the 'animal' column:"
]
},
{
"cell_type": "code",
"execution_count": 6,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"0 elephant\n",
"1 elephant\n",
"2 elephant\n",
"Name: animal, dtype: object\n"
]
}
],
"source": [
"print(my_zoo[:3]['animal'])"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"
\n",
"\n",
"What is we wanted to grab the name of our columns only, and save it as a list?"
]
},
{
"cell_type": "code",
"execution_count": 7,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"['animal', 'uniq_id', 'water_need']\n"
]
}
],
"source": [
"print(list(my_zoo.columns))"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"
\n",
"\n",
"You also have the ability to select multiple columns by simply inserting a list of column names as part of the subset command:"
]
},
{
"cell_type": "code",
"execution_count": 8,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
" animal uniq_id\n",
"0 elephant 1001\n",
"1 elephant 1002\n",
"2 elephant 1003\n",
"3 tiger 1004\n",
"4 tiger 1005\n",
"5 tiger 1006\n",
"6 tiger 1007\n",
"7 tiger 1008\n",
"8 zebra 1009\n",
"9 zebra 1010\n",
"10 zebra 1011\n",
"11 zebra 1012\n",
"12 zebra 1013\n",
"13 zebra 1014\n",
"14 zebra 1015\n",
"15 lion 1016\n",
"16 lion 1017\n",
"17 lion 1018\n",
"18 lion 1019\n",
"19 kangaroo 1020\n",
"20 kangaroo 1021\n",
"21 kangaroo 1022\n"
]
}
],
"source": [
"print(my_zoo[['animal','uniq_id']])"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"
\n",
"\n",
"# Do it yourself #1\n",
"\n",
"How would we subset our dataframe 'my_zoo' for the last 10 rows of the animal and water_need columns?\n",
"
\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"
\n",
"\n",
"What if we wanted save the rows for animals that have a water needed greater than or equal to 300?\n"
]
},
{
"cell_type": "code",
"execution_count": 9,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
" animal uniq_id water_need\n",
"0 elephant 1001 500\n",
"1 elephant 1002 600\n",
"2 elephant 1003 550\n",
"3 tiger 1004 300\n",
"4 tiger 1005 320\n",
"5 tiger 1006 330\n",
"7 tiger 1008 310\n",
"15 lion 1016 420\n",
"16 lion 1017 600\n",
"17 lion 1018 500\n",
"18 lion 1019 390\n",
"19 kangaroo 1020 410\n",
"20 kangaroo 1021 430\n",
"21 kangaroo 1022 410\n"
]
}
],
"source": [
"thirsty_animals = my_zoo[my_zoo['water_need'] >= 300]\n",
"print(thirsty_animals)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"
\n",
"\n",
"# Do it yourself #2\n",
"\n",
"What if I just wanted the ID numbers for animals that had a water requirement between 300-400? How would I do this? What animal requires this amount of water?\n",
"
"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"
\n",
"\n",
"\n",
"**Other useful functions and methods:**\n",
"\n",
"You can also add new columns to dateframe easily using Pandas. For example, lets say we wanted to add a new column called 'age', which we would fill in later. We can simply do the following to accomplish this task:\n"
]
},
{
"cell_type": "code",
"execution_count": 10,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
" animal uniq_id water_need age\n",
"0 elephant 1001 500 NaN\n",
"1 elephant 1002 600 NaN\n",
"2 elephant 1003 550 NaN\n",
"3 tiger 1004 300 NaN\n",
"4 tiger 1005 320 NaN\n",
"5 tiger 1006 330 NaN\n",
"6 tiger 1007 290 NaN\n",
"7 tiger 1008 310 NaN\n",
"8 zebra 1009 200 NaN\n",
"9 zebra 1010 220 NaN\n",
"10 zebra 1011 240 NaN\n",
"11 zebra 1012 230 NaN\n",
"12 zebra 1013 220 NaN\n",
"13 zebra 1014 100 NaN\n",
"14 zebra 1015 80 NaN\n",
"15 lion 1016 420 NaN\n",
"16 lion 1017 600 NaN\n",
"17 lion 1018 500 NaN\n",
"18 lion 1019 390 NaN\n",
"19 kangaroo 1020 410 NaN\n",
"20 kangaroo 1021 430 NaN\n",
"21 kangaroo 1022 410 NaN\n"
]
}
],
"source": [
"my_zoo['age'] = np.nan\n",
"print(my_zoo)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Here, I just set the value in the column as `NaN`, to signify that these need to be filled in at a later time."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"
\n",
"\n",
"You can use the `.loc` method to subset for a specific row number using an index. Lets saw we now know the age for the 2nd elephant in our data frame. To fill this in, we can use the `.at` method:"
]
},
{
"cell_type": "code",
"execution_count": 11,
"metadata": {},
"outputs": [],
"source": [
"my_zoo.at[2,'age'] = '4'"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Did it work?"
]
},
{
"cell_type": "code",
"execution_count": 12,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
" animal uniq_id water_need age\n",
"0 elephant 1001 500 NaN\n",
"1 elephant 1002 600 NaN\n",
"2 elephant 1003 550 4.0\n",
"3 tiger 1004 300 NaN\n",
"4 tiger 1005 320 NaN\n",
"5 tiger 1006 330 NaN\n",
"6 tiger 1007 290 NaN\n",
"7 tiger 1008 310 NaN\n",
"8 zebra 1009 200 NaN\n",
"9 zebra 1010 220 NaN\n",
"10 zebra 1011 240 NaN\n",
"11 zebra 1012 230 NaN\n",
"12 zebra 1013 220 NaN\n",
"13 zebra 1014 100 NaN\n",
"14 zebra 1015 80 NaN\n",
"15 lion 1016 420 NaN\n",
"16 lion 1017 600 NaN\n",
"17 lion 1018 500 NaN\n",
"18 lion 1019 390 NaN\n",
"19 kangaroo 1020 410 NaN\n",
"20 kangaroo 1021 430 NaN\n",
"21 kangaroo 1022 410 NaN\n"
]
}
],
"source": [
"print(my_zoo)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"
\n",
"\n",
"Another handy function is the `.replace` method, which will replace all instances of a specified value within our data frame. For example:"
]
},
{
"cell_type": "code",
"execution_count": 13,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
" animal uniq_id water_need age\n",
"0 elephant 1001 500 5.0\n",
"1 elephant 1002 600 5.0\n",
"2 elephant 1003 550 4.0\n",
"3 tiger 1004 300 5.0\n",
"4 tiger 1005 320 5.0\n",
"5 tiger 1006 330 5.0\n",
"6 tiger 1007 290 5.0\n",
"7 tiger 1008 310 5.0\n",
"8 zebra 1009 200 5.0\n",
"9 zebra 1010 220 5.0\n",
"10 zebra 1011 240 5.0\n",
"11 zebra 1012 230 5.0\n",
"12 zebra 1013 220 5.0\n",
"13 zebra 1014 100 5.0\n",
"14 zebra 1015 80 5.0\n",
"15 lion 1016 420 5.0\n",
"16 lion 1017 600 5.0\n",
"17 lion 1018 500 5.0\n",
"18 lion 1019 390 5.0\n",
"19 kangaroo 1020 410 5.0\n",
"20 kangaroo 1021 430 5.0\n",
"21 kangaroo 1022 410 5.0\n"
]
}
],
"source": [
"my_zoo = my_zoo.replace(np.nan, 5)\n",
"print(my_zoo)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Note that this command replaced all instances of `np.nan` with 5. Also note that the age of elephant #2 (ID 1002) remained unchanged since it was not equal to `np.nan`."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"
\n",
"\n",
"# Aggregating data\n",
"\n",
"Pandas dataframe structure makes it super easy to aggregate and manipulate data. For example, lets say we wanted to take an average of the water need for each animal type? We could this manually with this relatively short dataframe, but what if you needed to do this for a much larger zoo, with thousands of animals?!\n",
"Fortunately, this can be easily done in Python:\n"
]
},
{
"cell_type": "code",
"execution_count": 14,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"animal\n",
"elephant 550.000000\n",
"kangaroo 416.666667\n",
"lion 477.500000\n",
"tiger 310.000000\n",
"zebra 184.285714\n",
"Name: water_need, dtype: float64\n"
]
}
],
"source": [
"avg_water = my_zoo.groupby('animal')['water_need'].agg(np.mean) \n",
"print(avg_water)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"
\n",
"\n",
"We can also compute a bunch of other mathematical functions, simultaneously, in a single line!"
]
},
{
"cell_type": "code",
"execution_count": 15,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
" mean median std amax amin\n",
"animal \n",
"elephant 550.000000 550 50.000000 600 500\n",
"kangaroo 416.666667 410 11.547005 430 410\n",
"lion 477.500000 460 93.941471 600 390\n",
"tiger 310.000000 310 15.811388 330 290\n",
"zebra 184.285714 220 65.791880 240 80\n"
]
}
],
"source": [
"water_stats = my_zoo.groupby('animal')['water_need'].agg([np.mean,np.median,np.std,np.max,np.min])\n",
"print(water_stats)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"
\n",
"\n",
"# Working with data with timestamps\n",
"\n",
"Now, lets work with a data that has a column for time. Meteorological data often contains information about some quanitity that is being measured/modeled, in addition to the time that the measurement/modeled value was made at."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Lets take a quick peek at `module8_WBB.csv` with the Linux `more` command since we will be reading it in shortly.\n",
"\n",
"Do you see anything weird about this file that we may want to consider before reading it in with Pandas `pd.read_csv` function?\n",
"\n",
"Lets read in our file..."
]
},
{
"cell_type": "code",
"execution_count": 16,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
" Station_ID air_temp_set_1 relative_humidity_set_1 \\\n",
"Date_Time \n",
"2011-11-30 12:00:00-07:00 WBB 41.83 65.03 \n",
"2011-11-30 12:05:00-07:00 WBB 42.15 63.24 \n",
"2011-11-30 12:10:00-07:00 WBB 42.40 62.89 \n",
"2011-11-30 12:15:00-07:00 WBB 41.92 64.74 \n",
"2011-11-30 12:20:00-07:00 WBB 41.61 65.40 \n",
"2011-11-30 12:25:00-07:00 WBB 41.76 64.47 \n",
"2011-11-30 12:30:00-07:00 WBB 41.11 62.54 \n",
"2011-11-30 12:35:00-07:00 WBB 40.26 55.46 \n",
"2011-11-30 12:40:00-07:00 WBB 39.06 57.24 \n",
"2011-11-30 12:45:00-07:00 WBB 40.35 56.89 \n",
"2011-11-30 12:50:00-07:00 WBB 40.55 57.80 \n",
"2011-11-30 12:55:00-07:00 WBB 39.85 59.45 \n",
"2011-11-30 13:00:00-07:00 WBB 39.58 61.89 \n",
"2011-11-30 13:05:00-07:00 WBB 39.04 65.71 \n",
"2011-11-30 13:10:00-07:00 WBB 38.07 69.02 \n",
"2011-11-30 13:15:00-07:00 WBB 37.45 72.12 \n",
"2011-11-30 13:20:00-07:00 WBB 37.24 74.39 \n",
"2011-11-30 13:25:00-07:00 WBB 37.20 77.28 \n",
"2011-11-30 13:30:00-07:00 WBB 36.46 81.40 \n",
"2011-11-30 13:35:00-07:00 WBB 35.58 84.60 \n",
"2011-11-30 13:40:00-07:00 WBB 35.49 85.80 \n",
"2011-11-30 13:45:00-07:00 WBB 35.56 86.00 \n",
"2011-11-30 13:50:00-07:00 WBB 36.48 85.40 \n",
"2011-11-30 13:55:00-07:00 WBB 37.20 83.70 \n",
"2011-11-30 14:00:00-07:00 WBB 37.40 82.50 \n",
"2011-11-30 14:05:00-07:00 WBB 37.87 79.01 \n",
"2011-11-30 14:10:00-07:00 WBB 37.74 75.35 \n",
"2011-11-30 14:15:00-07:00 WBB 37.65 74.23 \n",
"2011-11-30 14:20:00-07:00 WBB 37.71 74.77 \n",
"2011-11-30 14:25:00-07:00 WBB 38.16 73.81 \n",
"... ... ... ... \n",
"2011-12-02 09:35:00-07:00 WBB 31.26 48.90 \n",
"2011-12-02 09:40:00-07:00 WBB 32.04 47.57 \n",
"2011-12-02 09:45:00-07:00 WBB 32.86 45.90 \n",
"2011-12-02 09:50:00-07:00 WBB 33.42 45.31 \n",
"2011-12-02 09:55:00-07:00 WBB 34.14 44.35 \n",
"2011-12-02 10:00:00-07:00 WBB 35.28 42.54 \n",
"2011-12-02 10:05:00-07:00 WBB 36.19 41.02 \n",
"2011-12-02 10:10:00-07:00 WBB 34.97 43.20 \n",
"2011-12-02 10:15:00-07:00 WBB 35.55 42.60 \n",
"2011-12-02 10:20:00-07:00 WBB 34.56 44.34 \n",
"2011-12-02 10:25:00-07:00 WBB 33.12 47.06 \n",
"2011-12-02 10:30:00-07:00 WBB 33.40 46.75 \n",
"2011-12-02 10:35:00-07:00 WBB 33.42 46.71 \n",
"2011-12-02 10:40:00-07:00 WBB 33.22 46.96 \n",
"2011-12-02 10:45:00-07:00 WBB 34.27 44.99 \n",
"2011-12-02 10:50:00-07:00 WBB 35.47 43.20 \n",
"2011-12-02 10:55:00-07:00 WBB 33.21 47.13 \n",
"2011-12-02 11:00:00-07:00 WBB 33.69 45.98 \n",
"2011-12-02 11:05:00-07:00 WBB 35.46 43.29 \n",
"2011-12-02 11:10:00-07:00 WBB 36.30 41.72 \n",
"2011-12-02 11:15:00-07:00 WBB 36.27 42.02 \n",
"2011-12-02 11:20:00-07:00 WBB 36.54 41.69 \n",
"2011-12-02 11:25:00-07:00 WBB 37.89 39.56 \n",
"2011-12-02 11:30:00-07:00 WBB 36.88 41.33 \n",
"2011-12-02 11:35:00-07:00 WBB 35.60 43.24 \n",
"2011-12-02 11:40:00-07:00 WBB 35.74 42.71 \n",
"2011-12-02 11:45:00-07:00 WBB 34.97 43.94 \n",
"2011-12-02 11:50:00-07:00 WBB 36.59 41.50 \n",
"2011-12-02 11:55:00-07:00 WBB 37.33 40.51 \n",
"2011-12-02 12:00:00-07:00 WBB 38.01 38.91 \n",
"\n",
" wind_speed_set_1 wind_direction_set_1 \\\n",
"Date_Time \n",
"2011-11-30 12:00:00-07:00 7.36 275.9 \n",
"2011-11-30 12:05:00-07:00 6.82 283.9 \n",
"2011-11-30 12:10:00-07:00 6.44 300.8 \n",
"2011-11-30 12:15:00-07:00 9.46 292.5 \n",
"2011-11-30 12:20:00-07:00 9.40 290.3 \n",
"2011-11-30 12:25:00-07:00 7.02 288.8 \n",
"2011-11-30 12:30:00-07:00 6.93 296.2 \n",
"2011-11-30 12:35:00-07:00 11.43 312.8 \n",
"2011-11-30 12:40:00-07:00 13.62 319.0 \n",
"2011-11-30 12:45:00-07:00 9.53 288.7 \n",
"2011-11-30 12:50:00-07:00 10.85 280.4 \n",
"2011-11-30 12:55:00-07:00 7.05 287.5 \n",
"2011-11-30 13:00:00-07:00 7.23 282.1 \n",
"2011-11-30 13:05:00-07:00 10.80 304.7 \n",
"2011-11-30 13:10:00-07:00 10.96 319.2 \n",
"2011-11-30 13:15:00-07:00 9.57 323.5 \n",
"2011-11-30 13:20:00-07:00 5.41 311.7 \n",
"2011-11-30 13:25:00-07:00 8.19 317.6 \n",
"2011-11-30 13:30:00-07:00 11.50 322.8 \n",
"2011-11-30 13:35:00-07:00 9.86 324.8 \n",
"2011-11-30 13:40:00-07:00 9.19 329.3 \n",
"2011-11-30 13:45:00-07:00 6.24 313.1 \n",
"2011-11-30 13:50:00-07:00 3.71 286.6 \n",
"2011-11-30 13:55:00-07:00 2.53 303.9 \n",
"2011-11-30 14:00:00-07:00 3.38 4.6 \n",
"2011-11-30 14:05:00-07:00 4.97 359.8 \n",
"2011-11-30 14:10:00-07:00 6.11 354.1 \n",
"2011-11-30 14:15:00-07:00 6.98 351.5 \n",
"2011-11-30 14:20:00-07:00 3.36 340.3 \n",
"2011-11-30 14:25:00-07:00 2.53 281.7 \n",
"... ... ... \n",
"2011-12-02 09:35:00-07:00 1.79 298.5 \n",
"2011-12-02 09:40:00-07:00 0.85 318.1 \n",
"2011-12-02 09:45:00-07:00 0.89 334.5 \n",
"2011-12-02 09:50:00-07:00 1.21 271.4 \n",
"2011-12-02 09:55:00-07:00 1.30 292.3 \n",
"2011-12-02 10:00:00-07:00 0.22 298.4 \n",
"2011-12-02 10:05:00-07:00 0.89 325.4 \n",
"2011-12-02 10:10:00-07:00 0.94 302.0 \n",
"2011-12-02 10:15:00-07:00 1.54 203.6 \n",
"2011-12-02 10:20:00-07:00 2.26 248.7 \n",
"2011-12-02 10:25:00-07:00 2.73 255.4 \n",
"2011-12-02 10:30:00-07:00 2.46 252.4 \n",
"2011-12-02 10:35:00-07:00 2.44 312.5 \n",
"2011-12-02 10:40:00-07:00 2.24 318.8 \n",
"2011-12-02 10:45:00-07:00 1.88 301.6 \n",
"2011-12-02 10:50:00-07:00 2.44 261.4 \n",
"2011-12-02 10:55:00-07:00 3.69 230.5 \n",
"2011-12-02 11:00:00-07:00 3.13 242.9 \n",
"2011-12-02 11:05:00-07:00 1.66 216.0 \n",
"2011-12-02 11:10:00-07:00 3.02 257.6 \n",
"2011-12-02 11:15:00-07:00 2.62 283.1 \n",
"2011-12-02 11:20:00-07:00 1.39 255.5 \n",
"2011-12-02 11:25:00-07:00 1.86 283.6 \n",
"2011-12-02 11:30:00-07:00 2.48 287.8 \n",
"2011-12-02 11:35:00-07:00 1.92 328.8 \n",
"2011-12-02 11:40:00-07:00 3.96 260.9 \n",
"2011-12-02 11:45:00-07:00 4.29 262.5 \n",
"2011-12-02 11:50:00-07:00 1.97 234.7 \n",
"2011-12-02 11:55:00-07:00 2.24 252.9 \n",
"2011-12-02 12:00:00-07:00 1.90 235.7 \n",
"\n",
" wind_gust_set_1 \n",
"Date_Time \n",
"2011-11-30 12:00:00-07:00 12.71 \n",
"2011-11-30 12:05:00-07:00 13.49 \n",
"2011-11-30 12:10:00-07:00 12.88 \n",
"2011-11-30 12:15:00-07:00 13.56 \n",
"2011-11-30 12:20:00-07:00 16.67 \n",
"2011-11-30 12:25:00-07:00 14.47 \n",
"2011-11-30 12:30:00-07:00 12.88 \n",
"2011-11-30 12:35:00-07:00 20.65 \n",
"2011-11-30 12:40:00-07:00 20.69 \n",
"2011-11-30 12:45:00-07:00 15.77 \n",
"2011-11-30 12:50:00-07:00 15.90 \n",
"2011-11-30 12:55:00-07:00 13.02 \n",
"2011-11-30 13:00:00-07:00 14.79 \n",
"2011-11-30 13:05:00-07:00 15.48 \n",
"2011-11-30 13:10:00-07:00 15.70 \n",
"2011-11-30 13:15:00-07:00 13.98 \n",
"2011-11-30 13:20:00-07:00 10.87 \n",
"2011-11-30 13:25:00-07:00 12.15 \n",
"2011-11-30 13:30:00-07:00 15.82 \n",
"2011-11-30 13:35:00-07:00 12.88 \n",
"2011-11-30 13:40:00-07:00 11.92 \n",
"2011-11-30 13:45:00-07:00 11.83 \n",
"2011-11-30 13:50:00-07:00 7.85 \n",
"2011-11-30 13:55:00-07:00 6.62 \n",
"2011-11-30 14:00:00-07:00 5.57 \n",
"2011-11-30 14:05:00-07:00 8.28 \n",
"2011-11-30 14:10:00-07:00 9.73 \n",
"2011-11-30 14:15:00-07:00 10.49 \n",
"2011-11-30 14:20:00-07:00 6.13 \n",
"2011-11-30 14:25:00-07:00 5.30 \n",
"... ... \n",
"2011-12-02 09:35:00-07:00 3.89 \n",
"2011-12-02 09:40:00-07:00 2.46 \n",
"2011-12-02 09:45:00-07:00 2.66 \n",
"2011-12-02 09:50:00-07:00 3.15 \n",
"2011-12-02 09:55:00-07:00 2.10 \n",
"2011-12-02 10:00:00-07:00 1.05 \n",
"2011-12-02 10:05:00-07:00 2.19 \n",
"2011-12-02 10:10:00-07:00 2.24 \n",
"2011-12-02 10:15:00-07:00 3.38 \n",
"2011-12-02 10:20:00-07:00 5.95 \n",
"2011-12-02 10:25:00-07:00 4.52 \n",
"2011-12-02 10:30:00-07:00 4.00 \n",
"2011-12-02 10:35:00-07:00 4.56 \n",
"2011-12-02 10:40:00-07:00 4.21 \n",
"2011-12-02 10:45:00-07:00 4.25 \n",
"2011-12-02 10:50:00-07:00 4.88 \n",
"2011-12-02 10:55:00-07:00 5.12 \n",
"2011-12-02 11:00:00-07:00 4.61 \n",
"2011-12-02 11:05:00-07:00 3.80 \n",
"2011-12-02 11:10:00-07:00 5.91 \n",
"2011-12-02 11:15:00-07:00 4.83 \n",
"2011-12-02 11:20:00-07:00 3.74 \n",
"2011-12-02 11:25:00-07:00 4.16 \n",
"2011-12-02 11:30:00-07:00 4.05 \n",
"2011-12-02 11:35:00-07:00 4.29 \n",
"2011-12-02 11:40:00-07:00 6.76 \n",
"2011-12-02 11:45:00-07:00 5.79 \n",
"2011-12-02 11:50:00-07:00 4.25 \n",
"2011-12-02 11:55:00-07:00 4.05 \n",
"2011-12-02 12:00:00-07:00 3.47 \n",
"\n",
"[577 rows x 6 columns]\n"
]
}
],
"source": [
"dat = pd.read_csv('module8_WBB.csv',sep=',',skiprows=6,index_col=1,parse_dates=True)\n",
"print(dat)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Wow! Easy! Everything looks like it was properly formatted, at least visually. Lets double check through. Using the dtypes method, we can check the data type of each column in our 'dat' dataframe:"
]
},
{
"cell_type": "code",
"execution_count": 17,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"Station_ID object\n",
"air_temp_set_1 float64\n",
"relative_humidity_set_1 float64\n",
"wind_speed_set_1 float64\n",
"wind_direction_set_1 float64\n",
"wind_gust_set_1 float64\n",
"dtype: object\n"
]
}
],
"source": [
"print(dat.dtypes)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"
\n",
"\n",
"Now that our time column is properly formatted, we can easily manipulate our dateframe, such as resampling the data to different time itervals, or subsetting the dataframe based on a time range."
]
},
{
"cell_type": "code",
"execution_count": 18,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
" air_temp_set_1 relative_humidity_set_1 \\\n",
"Date_Time \n",
"2011-11-30 12:00:00-07:00 41.070833 61.262500 \n",
"2011-11-30 13:00:00-07:00 37.112500 77.275833 \n",
"2011-11-30 14:00:00-07:00 37.794167 76.843333 \n",
"2011-11-30 15:00:00-07:00 38.309167 75.110833 \n",
"2011-11-30 16:00:00-07:00 36.626667 81.808333 \n",
"2011-11-30 17:00:00-07:00 36.086667 79.774167 \n",
"2011-11-30 18:00:00-07:00 35.072500 82.941667 \n",
"2011-11-30 19:00:00-07:00 36.170833 76.920000 \n",
"2011-11-30 20:00:00-07:00 36.368333 75.253333 \n",
"2011-11-30 21:00:00-07:00 35.672500 71.585000 \n",
"2011-11-30 22:00:00-07:00 36.262500 61.963333 \n",
"2011-11-30 23:00:00-07:00 36.397500 60.644167 \n",
"2011-12-01 00:00:00-07:00 35.710833 62.371667 \n",
"2011-12-01 01:00:00-07:00 34.572500 64.782500 \n",
"2011-12-01 02:00:00-07:00 36.801667 49.818333 \n",
"2011-12-01 03:00:00-07:00 38.271667 37.009167 \n",
"2011-12-01 04:00:00-07:00 37.715833 36.103333 \n",
"2011-12-01 05:00:00-07:00 37.290000 35.842500 \n",
"2011-12-01 06:00:00-07:00 36.497500 34.757500 \n",
"2011-12-01 07:00:00-07:00 35.994167 33.582500 \n",
"2011-12-01 08:00:00-07:00 36.060000 31.395000 \n",
"2011-12-01 09:00:00-07:00 36.868333 28.220000 \n",
"2011-12-01 10:00:00-07:00 37.130833 28.402500 \n",
"2011-12-01 11:00:00-07:00 37.059167 29.966667 \n",
"2011-12-01 12:00:00-07:00 36.068333 32.129167 \n",
"2011-12-01 13:00:00-07:00 35.382500 34.141667 \n",
"2011-12-01 14:00:00-07:00 36.747500 33.377500 \n",
"2011-12-01 15:00:00-07:00 36.472500 33.803333 \n",
"2011-12-01 16:00:00-07:00 36.511667 33.147500 \n",
"2011-12-01 17:00:00-07:00 34.111667 37.075000 \n",
"2011-12-01 18:00:00-07:00 31.890000 42.536667 \n",
"2011-12-01 19:00:00-07:00 31.927500 42.229167 \n",
"2011-12-01 20:00:00-07:00 32.830000 38.487500 \n",
"2011-12-01 21:00:00-07:00 32.498333 38.027500 \n",
"2011-12-01 22:00:00-07:00 31.202500 40.455000 \n",
"2011-12-01 23:00:00-07:00 31.441667 38.649167 \n",
"2011-12-02 00:00:00-07:00 30.979167 40.770000 \n",
"2011-12-02 01:00:00-07:00 31.785000 40.255833 \n",
"2011-12-02 02:00:00-07:00 31.356667 44.642500 \n",
"2011-12-02 03:00:00-07:00 31.098333 43.977500 \n",
"2011-12-02 04:00:00-07:00 29.100833 49.737500 \n",
"2011-12-02 05:00:00-07:00 28.359167 50.650000 \n",
"2011-12-02 06:00:00-07:00 27.214167 54.053333 \n",
"2011-12-02 07:00:00-07:00 25.525833 60.672500 \n",
"2011-12-02 08:00:00-07:00 28.213333 54.267500 \n",
"2011-12-02 09:00:00-07:00 32.146667 47.738333 \n",
"2011-12-02 10:00:00-07:00 34.388333 44.708333 \n",
"2011-12-02 11:00:00-07:00 36.105000 42.290833 \n",
"2011-12-02 12:00:00-07:00 38.010000 38.910000 \n",
"\n",
" wind_speed_set_1 wind_direction_set_1 \\\n",
"Date_Time \n",
"2011-11-30 12:00:00-07:00 8.825833 293.066667 \n",
"2011-11-30 13:00:00-07:00 7.932500 311.608333 \n",
"2011-11-30 14:00:00-07:00 5.360833 276.608333 \n",
"2011-11-30 15:00:00-07:00 5.049167 274.108333 \n",
"2011-11-30 16:00:00-07:00 3.900833 299.675000 \n",
"2011-11-30 17:00:00-07:00 10.550000 323.441667 \n",
"2011-11-30 18:00:00-07:00 5.983333 216.864167 \n",
"2011-11-30 19:00:00-07:00 2.363333 265.808333 \n",
"2011-11-30 20:00:00-07:00 1.858333 205.978333 \n",
"2011-11-30 21:00:00-07:00 3.364167 175.933333 \n",
"2011-11-30 22:00:00-07:00 2.381667 211.918333 \n",
"2011-11-30 23:00:00-07:00 2.191667 244.408333 \n",
"2011-12-01 00:00:00-07:00 3.190000 209.165000 \n",
"2011-12-01 01:00:00-07:00 2.494167 227.047500 \n",
"2011-12-01 02:00:00-07:00 8.749167 264.300000 \n",
"2011-12-01 03:00:00-07:00 27.408333 96.825000 \n",
"2011-12-01 04:00:00-07:00 28.243333 66.291667 \n",
"2011-12-01 05:00:00-07:00 23.196667 66.730833 \n",
"2011-12-01 06:00:00-07:00 35.751667 66.654167 \n",
"2011-12-01 07:00:00-07:00 39.820000 65.290000 \n",
"2011-12-01 08:00:00-07:00 39.189167 62.622500 \n",
"2011-12-01 09:00:00-07:00 45.686667 60.757500 \n",
"2011-12-01 10:00:00-07:00 24.091667 74.785833 \n",
"2011-12-01 11:00:00-07:00 17.085833 78.295000 \n",
"2011-12-01 12:00:00-07:00 20.679167 95.750000 \n",
"2011-12-01 13:00:00-07:00 9.855833 145.594167 \n",
"2011-12-01 14:00:00-07:00 11.904167 143.310000 \n",
"2011-12-01 15:00:00-07:00 11.442500 98.513333 \n",
"2011-12-01 16:00:00-07:00 10.577500 93.065000 \n",
"2011-12-01 17:00:00-07:00 17.293333 82.720833 \n",
"2011-12-01 18:00:00-07:00 32.535000 80.155833 \n",
"2011-12-01 19:00:00-07:00 24.338333 84.640000 \n",
"2011-12-01 20:00:00-07:00 25.758333 62.915000 \n",
"2011-12-01 21:00:00-07:00 25.779167 66.466667 \n",
"2011-12-01 22:00:00-07:00 13.525000 49.516667 \n",
"2011-12-01 23:00:00-07:00 15.765000 41.401667 \n",
"2011-12-02 00:00:00-07:00 6.695833 85.031667 \n",
"2011-12-02 01:00:00-07:00 7.520000 45.764167 \n",
"2011-12-02 02:00:00-07:00 2.392500 112.525000 \n",
"2011-12-02 03:00:00-07:00 3.465000 50.455000 \n",
"2011-12-02 04:00:00-07:00 2.167500 188.166667 \n",
"2011-12-02 05:00:00-07:00 2.823333 186.527500 \n",
"2011-12-02 06:00:00-07:00 1.528333 168.907500 \n",
"2011-12-02 07:00:00-07:00 1.802500 149.603333 \n",
"2011-12-02 08:00:00-07:00 2.853333 243.021667 \n",
"2011-12-02 09:00:00-07:00 1.479167 274.033333 \n",
"2011-12-02 10:00:00-07:00 1.977500 275.891667 \n",
"2011-12-02 11:00:00-07:00 2.545000 263.858333 \n",
"2011-12-02 12:00:00-07:00 1.900000 235.700000 \n",
"\n",
" wind_gust_set_1 \n",
"Date_Time \n",
"2011-11-30 12:00:00-07:00 15.224167 \n",
"2011-11-30 13:00:00-07:00 12.490833 \n",
"2011-11-30 14:00:00-07:00 8.716667 \n",
"2011-11-30 15:00:00-07:00 9.271667 \n",
"2011-11-30 16:00:00-07:00 6.715000 \n",
"2011-11-30 17:00:00-07:00 13.445000 \n",
"2011-11-30 18:00:00-07:00 8.852500 \n",
"2011-11-30 19:00:00-07:00 3.912500 \n",
"2011-11-30 20:00:00-07:00 3.116667 \n",
"2011-11-30 21:00:00-07:00 5.665000 \n",
"2011-11-30 22:00:00-07:00 4.261667 \n",
"2011-11-30 23:00:00-07:00 4.582500 \n",
"2011-12-01 00:00:00-07:00 5.182500 \n",
"2011-12-01 01:00:00-07:00 5.108333 \n",
"2011-12-01 02:00:00-07:00 17.446667 \n",
"2011-12-01 03:00:00-07:00 42.325833 \n",
"2011-12-01 04:00:00-07:00 44.200833 \n",
"2011-12-01 05:00:00-07:00 42.333333 \n",
"2011-12-01 06:00:00-07:00 53.620833 \n",
"2011-12-01 07:00:00-07:00 57.690000 \n",
"2011-12-01 08:00:00-07:00 55.303333 \n",
"2011-12-01 09:00:00-07:00 61.510833 \n",
"2011-12-01 10:00:00-07:00 38.980833 \n",
"2011-12-01 11:00:00-07:00 25.346667 \n",
"2011-12-01 12:00:00-07:00 30.819167 \n",
"2011-12-01 13:00:00-07:00 17.442500 \n",
"2011-12-01 14:00:00-07:00 22.301667 \n",
"2011-12-01 15:00:00-07:00 23.310833 \n",
"2011-12-01 16:00:00-07:00 20.975000 \n",
"2011-12-01 17:00:00-07:00 26.629167 \n",
"2011-12-01 18:00:00-07:00 42.610833 \n",
"2011-12-01 19:00:00-07:00 34.619167 \n",
"2011-12-01 20:00:00-07:00 39.640000 \n",
"2011-12-01 21:00:00-07:00 38.998333 \n",
"2011-12-01 22:00:00-07:00 24.290833 \n",
"2011-12-01 23:00:00-07:00 23.865000 \n",
"2011-12-02 00:00:00-07:00 12.403333 \n",
"2011-12-02 01:00:00-07:00 12.390833 \n",
"2011-12-02 02:00:00-07:00 4.327500 \n",
"2011-12-02 03:00:00-07:00 5.329167 \n",
"2011-12-02 04:00:00-07:00 3.623333 \n",
"2011-12-02 05:00:00-07:00 4.056667 \n",
"2011-12-02 06:00:00-07:00 2.994167 \n",
"2011-12-02 07:00:00-07:00 2.645000 \n",
"2011-12-02 08:00:00-07:00 4.336667 \n",
"2011-12-02 09:00:00-07:00 3.063333 \n",
"2011-12-02 10:00:00-07:00 3.862500 \n",
"2011-12-02 11:00:00-07:00 4.686667 \n",
"2011-12-02 12:00:00-07:00 3.470000 \n"
]
}
],
"source": [
"dat_1hour = dat.resample('60Min').mean()\n",
"print(dat_1hour)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"⚠️⚠️⚠️ Before moving on, is there something sloppy that I assumed here? ⚠️⚠️⚠️\n",
"\n",
"\n",
"What can we do? Lets decompose our wind speed and direction into u- and v-wind components, and then take the average for each hour!\n",
"Then we can just convert our u- and v-wind components back into a wind speed and direction!"
]
},
{
"cell_type": "code",
"execution_count": 19,
"metadata": {},
"outputs": [],
"source": [
"u = -1*dat['wind_speed_set_1']*np.sin(dat['wind_direction_set_1']*(np.pi/180))\n",
"v = -1*dat['wind_speed_set_1']*np.cos(dat['wind_direction_set_1']*(np.pi/180))\n",
" \n",
"dat['u_wind'] = u\n",
"dat['v_wind'] = v\n",
" \n",
"dat_1hour = dat.resample('60Min').mean()\n",
" \n",
"dat_1hour['wind_speed_set_1'] = np.sqrt(dat_1hour['u_wind']**2 + dat_1hour['v_wind']**2)\n",
"dat_1hour['wind_direction_set_1'] = (270-(np.arctan2(dat_1hour['v_wind'],dat_1hour['u_wind'])*(180/np.pi)))%360\n",
" "
]
},
{
"cell_type": "code",
"execution_count": 20,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"[ 5.77777778 4.21111111 3.71111111 4.41111111 2.78888889 2.37777778\n",
" 2.31111111 2.71111111 2.82777778 2.32777778 2.72777778 2.85\n",
" 2.27222222 1.66111111 3.5 3.68888889 3.46111111 3.12222222\n",
" 2.77222222 2.37777778 2.51111111 3.22777778 3.45 3.61111111\n",
" 2.56111111 2.77777778 3.27222222 2.85 2.87222222 1.81111111\n",
" 0.22222222 0.92222222 1.01111111 0.66111111 0.43888889 0.27222222\n",
" -0.11111111 0.16111111 0.01111111 -0.03888889 -0.53888889 -1.48888889\n",
" -2.03888889 -2.9 0.28888889 1.18888889 2.32777778 3.27222222\n",
" 3.33888889]\n"
]
}
],
"source": [
"dat['air_temp_set_1'] = (dat['air_temp_set_1'] - 32) * (5/9)\n",
"dat1_hr = dat.resample('60Min').min()\n",
"dat1_hr = dat.resample('60Min').max()\n",
"\n",
"print(np.array(dat1_hr['air_temp_set_1']))"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"
\n",
"\n",
"# Do it yourself #3\n",
"\n",
"Can you compute the hourly max and min temperature in degrees of Celsius? Temperature is currently being reported in Fahrenheit."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"
\n",
"\n",
"**Time conversion:** There may also be cases where you will need to convert your time objects between UTC and LST. For example, most environmental data sets are reported in UTC. However, it may be more intuitive to look at the data in LST, especially when looking at data such as temperature and relative humidity. Fortunately, Pandas makes it *relatively* easy to convert between time zones.\n"
]
},
{
"cell_type": "code",
"execution_count": 21,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"DatetimeIndex(['2011-11-30 12:00:00-07:00', '2011-11-30 12:05:00-07:00',\n",
" '2011-11-30 12:10:00-07:00', '2011-11-30 12:15:00-07:00',\n",
" '2011-11-30 12:20:00-07:00', '2011-11-30 12:25:00-07:00',\n",
" '2011-11-30 12:30:00-07:00', '2011-11-30 12:35:00-07:00',\n",
" '2011-11-30 12:40:00-07:00', '2011-11-30 12:45:00-07:00',\n",
" ...\n",
" '2011-12-02 11:15:00-07:00', '2011-12-02 11:20:00-07:00',\n",
" '2011-12-02 11:25:00-07:00', '2011-12-02 11:30:00-07:00',\n",
" '2011-12-02 11:35:00-07:00', '2011-12-02 11:40:00-07:00',\n",
" '2011-12-02 11:45:00-07:00', '2011-12-02 11:50:00-07:00',\n",
" '2011-12-02 11:55:00-07:00', '2011-12-02 12:00:00-07:00'],\n",
" dtype='datetime64[ns, pytz.FixedOffset(-420)]', name='Date_Time', length=577, freq=None)\n"
]
}
],
"source": [
"#Before time conversion...\n",
"print(dat.index)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"
\n",
"Here, python assumed that the timestamp is in MT (hence the -07:00) since our timestamp had 'MST' when we read it in. "
]
},
{
"cell_type": "code",
"execution_count": 27,
"metadata": {},
"outputs": [],
"source": [
"#Lets apply a time conversion that converts our times in MST to UTC\n",
"dat.index = dat.index.tz_convert('UTC')"
]
},
{
"cell_type": "code",
"execution_count": 28,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"DatetimeIndex(['2011-11-30 19:00:00+00:00', '2011-11-30 19:05:00+00:00',\n",
" '2011-11-30 19:10:00+00:00', '2011-11-30 19:15:00+00:00',\n",
" '2011-11-30 19:20:00+00:00', '2011-11-30 19:25:00+00:00',\n",
" '2011-11-30 19:30:00+00:00', '2011-11-30 19:35:00+00:00',\n",
" '2011-11-30 19:40:00+00:00', '2011-11-30 19:45:00+00:00',\n",
" ...\n",
" '2011-12-02 18:15:00+00:00', '2011-12-02 18:20:00+00:00',\n",
" '2011-12-02 18:25:00+00:00', '2011-12-02 18:30:00+00:00',\n",
" '2011-12-02 18:35:00+00:00', '2011-12-02 18:40:00+00:00',\n",
" '2011-12-02 18:45:00+00:00', '2011-12-02 18:50:00+00:00',\n",
" '2011-12-02 18:55:00+00:00', '2011-12-02 19:00:00+00:00'],\n",
" dtype='datetime64[ns, UTC]', name='Date_Time', length=577, freq=None)\n"
]
}
],
"source": [
"#Print times after the conversion...\n",
"print(dat.index)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Did anything happen?"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"
\n",
"\n",
"**Cautionary tale:** Working with time objects can often be one of the more frustrating parts of programming, and this is often where a lot of bugs may arise. So always becareful when working with these data types! Also, do not get too discouraged. Even people like myself who have been programming for years often run into problems with time objects!\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Reading in timestamp and assigning it to the pandas index makes it really easy to filter the data accordingly. For example, lets select a range of data we want to look at..."
]
},
{
"cell_type": "code",
"execution_count": 29,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
" Station_ID air_temp_set_1 relative_humidity_set_1 \\\n",
"Date_Time \n",
"2011-12-01 00:00:00+00:00 WBB 2.350000 80.70 \n",
"2011-12-01 00:05:00+00:00 WBB 2.322222 79.28 \n",
"2011-12-01 00:10:00+00:00 WBB 2.277778 78.61 \n",
"2011-12-01 00:15:00+00:00 WBB 2.327778 78.33 \n",
"2011-12-01 00:20:00+00:00 WBB 2.377778 78.26 \n",
"2011-12-01 00:25:00+00:00 WBB 2.327778 78.83 \n",
"2011-12-01 00:30:00+00:00 WBB 2.338889 79.03 \n",
"2011-12-01 00:35:00+00:00 WBB 2.350000 79.28 \n",
"2011-12-01 00:40:00+00:00 WBB 2.311111 79.87 \n",
"2011-12-01 00:45:00+00:00 WBB 2.261111 80.30 \n",
"2011-12-01 00:50:00+00:00 WBB 2.072222 81.90 \n",
"2011-12-01 00:55:00+00:00 WBB 1.927778 82.90 \n",
"2011-12-01 01:00:00+00:00 WBB 1.861111 83.00 \n",
"2011-12-01 01:05:00+00:00 WBB 1.827778 83.20 \n",
"2011-12-01 01:10:00+00:00 WBB 1.838889 81.20 \n",
"2011-12-01 01:15:00+00:00 WBB 1.577778 82.10 \n",
"2011-12-01 01:20:00+00:00 WBB 1.338889 83.40 \n",
"2011-12-01 01:25:00+00:00 WBB 1.188889 84.90 \n",
"2011-12-01 01:30:00+00:00 WBB 1.338889 84.80 \n",
"2011-12-01 01:35:00+00:00 WBB 1.461111 84.90 \n",
"2011-12-01 01:40:00+00:00 WBB 1.688889 84.20 \n",
"2011-12-01 01:45:00+00:00 WBB 1.938889 82.70 \n",
"2011-12-01 01:50:00+00:00 WBB 2.111111 80.70 \n",
"2011-12-01 01:55:00+00:00 WBB 2.311111 80.20 \n",
"2011-12-01 02:00:00+00:00 WBB 2.188889 80.20 \n",
"2011-12-01 02:05:00+00:00 WBB 2.111111 81.20 \n",
"2011-12-01 02:10:00+00:00 WBB 2.072222 79.31 \n",
"2011-12-01 02:15:00+00:00 WBB 2.111111 78.24 \n",
"2011-12-01 02:20:00+00:00 WBB 2.138889 76.21 \n",
"2011-12-01 02:25:00+00:00 WBB 2.388889 72.50 \n",
"... ... ... ... \n",
"2011-12-01 09:35:00+00:00 WBB 3.338889 43.54 \n",
"2011-12-01 09:40:00+00:00 WBB 3.261111 45.34 \n",
"2011-12-01 09:45:00+00:00 WBB 3.311111 43.63 \n",
"2011-12-01 09:50:00+00:00 WBB 3.500000 41.62 \n",
"2011-12-01 09:55:00+00:00 WBB 3.350000 43.36 \n",
"2011-12-01 10:00:00+00:00 WBB 3.388889 40.87 \n",
"2011-12-01 10:05:00+00:00 WBB 3.472222 40.19 \n",
"2011-12-01 10:10:00+00:00 WBB 3.327778 41.26 \n",
"2011-12-01 10:15:00+00:00 WBB 3.338889 41.63 \n",
"2011-12-01 10:20:00+00:00 WBB 3.372222 41.56 \n",
"2011-12-01 10:25:00+00:00 WBB 3.427778 35.37 \n",
"2011-12-01 10:30:00+00:00 WBB 3.561111 33.83 \n",
"2011-12-01 10:35:00+00:00 WBB 3.577778 33.60 \n",
"2011-12-01 10:40:00+00:00 WBB 3.688889 33.14 \n",
"2011-12-01 10:45:00+00:00 WBB 3.588889 33.82 \n",
"2011-12-01 10:50:00+00:00 WBB 3.627778 33.58 \n",
"2011-12-01 10:55:00+00:00 WBB 3.438889 35.26 \n",
"2011-12-01 11:00:00+00:00 WBB 3.427778 35.25 \n",
"2011-12-01 11:05:00+00:00 WBB 3.422222 35.10 \n",
"2011-12-01 11:10:00+00:00 WBB 3.461111 34.99 \n",
"2011-12-01 11:15:00+00:00 WBB 3.238889 36.07 \n",
"2011-12-01 11:20:00+00:00 WBB 3.238889 35.65 \n",
"2011-12-01 11:25:00+00:00 WBB 3.177778 35.88 \n",
"2011-12-01 11:30:00+00:00 WBB 3.072222 36.19 \n",
"2011-12-01 11:35:00+00:00 WBB 3.022222 36.51 \n",
"2011-12-01 11:40:00+00:00 WBB 2.888889 37.14 \n",
"2011-12-01 11:45:00+00:00 WBB 2.977778 36.66 \n",
"2011-12-01 11:50:00+00:00 WBB 3.038889 36.94 \n",
"2011-12-01 11:55:00+00:00 WBB 3.138889 36.86 \n",
"2011-12-01 12:00:00+00:00 WBB 3.111111 36.89 \n",
"\n",
" wind_speed_set_1 wind_direction_set_1 \\\n",
"Date_Time \n",
"2011-12-01 00:00:00+00:00 8.86 314.90 \n",
"2011-12-01 00:05:00+00:00 10.67 319.00 \n",
"2011-12-01 00:10:00+00:00 11.30 322.40 \n",
"2011-12-01 00:15:00+00:00 11.32 319.90 \n",
"2011-12-01 00:20:00+00:00 10.49 320.30 \n",
"2011-12-01 00:25:00+00:00 10.02 324.20 \n",
"2011-12-01 00:30:00+00:00 11.61 329.50 \n",
"2011-12-01 00:35:00+00:00 11.18 323.10 \n",
"2011-12-01 00:40:00+00:00 10.38 329.70 \n",
"2011-12-01 00:45:00+00:00 10.54 320.60 \n",
"2011-12-01 00:50:00+00:00 10.54 324.40 \n",
"2011-12-01 00:55:00+00:00 9.69 333.30 \n",
"2011-12-01 01:00:00+00:00 8.79 345.10 \n",
"2011-12-01 01:05:00+00:00 7.72 356.80 \n",
"2011-12-01 01:10:00+00:00 11.10 358.10 \n",
"2011-12-01 01:15:00+00:00 11.50 356.30 \n",
"2011-12-01 01:20:00+00:00 11.61 11.69 \n",
"2011-12-01 01:25:00+00:00 7.81 27.91 \n",
"2011-12-01 01:30:00+00:00 5.17 63.33 \n",
"2011-12-01 01:35:00+00:00 1.68 58.64 \n",
"2011-12-01 01:40:00+00:00 2.01 200.90 \n",
"2011-12-01 01:45:00+00:00 2.33 300.90 \n",
"2011-12-01 01:50:00+00:00 1.43 282.70 \n",
"2011-12-01 01:55:00+00:00 0.65 240.00 \n",
"2011-12-01 02:00:00+00:00 0.40 137.70 \n",
"2011-12-01 02:05:00+00:00 0.60 329.10 \n",
"2011-12-01 02:10:00+00:00 3.40 325.10 \n",
"2011-12-01 02:15:00+00:00 3.89 336.00 \n",
"2011-12-01 02:20:00+00:00 3.18 336.90 \n",
"2011-12-01 02:25:00+00:00 1.81 349.00 \n",
"... ... ... \n",
"2011-12-01 09:35:00+00:00 11.05 354.90 \n",
"2011-12-01 09:40:00+00:00 8.93 326.20 \n",
"2011-12-01 09:45:00+00:00 10.20 93.40 \n",
"2011-12-01 09:50:00+00:00 6.24 256.80 \n",
"2011-12-01 09:55:00+00:00 8.21 317.90 \n",
"2011-12-01 10:00:00+00:00 11.79 58.46 \n",
"2011-12-01 10:05:00+00:00 12.35 19.09 \n",
"2011-12-01 10:10:00+00:00 8.23 18.18 \n",
"2011-12-01 10:15:00+00:00 4.52 352.50 \n",
"2011-12-01 10:20:00+00:00 5.59 310.60 \n",
"2011-12-01 10:25:00+00:00 22.24 59.96 \n",
"2011-12-01 10:30:00+00:00 33.58 51.70 \n",
"2011-12-01 10:35:00+00:00 41.18 56.10 \n",
"2011-12-01 10:40:00+00:00 50.64 58.60 \n",
"2011-12-01 10:45:00+00:00 49.77 56.80 \n",
"2011-12-01 10:50:00+00:00 50.76 58.54 \n",
"2011-12-01 10:55:00+00:00 38.25 61.37 \n",
"2011-12-01 11:00:00+00:00 36.95 58.87 \n",
"2011-12-01 11:05:00+00:00 36.91 60.30 \n",
"2011-12-01 11:10:00+00:00 29.93 63.03 \n",
"2011-12-01 11:15:00+00:00 29.86 60.46 \n",
"2011-12-01 11:20:00+00:00 30.00 61.33 \n",
"2011-12-01 11:25:00+00:00 28.99 62.26 \n",
"2011-12-01 11:30:00+00:00 28.25 61.94 \n",
"2011-12-01 11:35:00+00:00 23.35 66.40 \n",
"2011-12-01 11:40:00+00:00 22.77 73.16 \n",
"2011-12-01 11:45:00+00:00 26.35 73.13 \n",
"2011-12-01 11:50:00+00:00 24.67 82.40 \n",
"2011-12-01 11:55:00+00:00 20.89 72.22 \n",
"2011-12-01 12:00:00+00:00 22.75 74.26 \n",
"\n",
" wind_gust_set_1 u_wind v_wind \n",
"Date_Time \n",
"2011-12-01 00:00:00+00:00 11.43 6.275891 -6.254022 \n",
"2011-12-01 00:05:00+00:00 13.60 7.000150 -8.052751 \n",
"2011-12-01 00:10:00+00:00 13.47 6.894640 -8.952873 \n",
"2011-12-01 00:15:00+00:00 14.47 7.291479 -8.658910 \n",
"2011-12-01 00:20:00+00:00 13.76 6.700674 -8.071001 \n",
"2011-12-01 00:25:00+00:00 12.28 5.861276 -8.126859 \n",
"2011-12-01 00:30:00+00:00 14.52 5.892520 -10.003515 \n",
"2011-12-01 00:35:00+00:00 14.83 6.712698 -8.940474 \n",
"2011-12-01 00:40:00+00:00 13.65 5.236997 -8.962046 \n",
"2011-12-01 00:45:00+00:00 12.93 6.690060 -8.144612 \n",
"2011-12-01 00:50:00+00:00 13.69 6.135576 -8.570082 \n",
"2011-12-01 00:55:00+00:00 12.71 4.353901 -8.656769 \n",
"2011-12-01 01:00:00+00:00 13.02 2.260197 -8.494446 \n",
"2011-12-01 01:05:00+00:00 11.01 0.430942 -7.707963 \n",
"2011-12-01 01:10:00+00:00 16.31 0.368022 -11.093897 \n",
"2011-12-01 01:15:00+00:00 15.97 0.742122 -11.476030 \n",
"2011-12-01 01:20:00+00:00 16.26 -2.352376 -11.369188 \n",
"2011-12-01 01:25:00+00:00 10.04 -3.655736 -6.901572 \n",
"2011-12-01 01:30:00+00:00 8.12 -4.619946 -2.320561 \n",
"2011-12-01 01:35:00+00:00 3.20 -1.434576 -0.874295 \n",
"2011-12-01 01:40:00+00:00 3.15 0.717043 1.877751 \n",
"2011-12-01 01:45:00+00:00 3.89 1.999291 -1.196551 \n",
"2011-12-01 01:50:00+00:00 3.02 1.395014 -0.314380 \n",
"2011-12-01 01:55:00+00:00 2.24 0.562917 0.325000 \n",
"2011-12-01 02:00:00+00:00 1.52 -0.269205 0.295852 \n",
"2011-12-01 02:05:00+00:00 3.15 0.308125 -0.514839 \n",
"2011-12-01 02:10:00+00:00 4.21 1.945296 -2.788516 \n",
"2011-12-01 02:15:00+00:00 5.17 1.582206 -3.553692 \n",
"2011-12-01 02:20:00+00:00 5.03 1.247632 -2.925032 \n",
"2011-12-01 02:25:00+00:00 3.78 0.345364 -1.776745 \n",
"... ... ... ... \n",
"2011-12-01 09:35:00+00:00 18.23 0.982282 -11.006254 \n",
"2011-12-01 09:40:00+00:00 20.29 4.967720 -7.420691 \n",
"2011-12-01 09:45:00+00:00 26.35 -10.182046 0.604925 \n",
"2011-12-01 09:50:00+00:00 17.09 6.075132 1.424909 \n",
"2011-12-01 09:55:00+00:00 17.22 5.504203 -6.091622 \n",
"2011-12-01 10:00:00+00:00 29.73 -10.048324 -6.167275 \n",
"2011-12-01 10:05:00+00:00 21.83 -4.039104 -11.670824 \n",
"2011-12-01 10:10:00+00:00 17.87 -2.567787 -7.819167 \n",
"2011-12-01 10:15:00+00:00 11.48 0.589978 -4.481331 \n",
"2011-12-01 10:20:00+00:00 12.10 4.244327 -3.637828 \n",
"2011-12-01 10:25:00+00:00 49.57 -19.252637 -11.133444 \n",
"2011-12-01 10:30:00+00:00 48.92 -26.352791 -20.812180 \n",
"2011-12-01 10:35:00+00:00 56.46 -34.179906 -22.967944 \n",
"2011-12-01 10:40:00+00:00 68.83 -43.223812 -26.383928 \n",
"2011-12-01 10:45:00+00:00 69.43 -41.645760 -27.252222 \n",
"2011-12-01 10:50:00+00:00 67.47 -43.298520 -26.491806 \n",
"2011-12-01 10:55:00+00:00 54.22 -33.573257 -18.327545 \n",
"2011-12-01 11:00:00+00:00 54.67 -31.629071 -19.102470 \n",
"2011-12-01 11:05:00+00:00 54.87 -32.061189 -18.287379 \n",
"2011-12-01 11:10:00+00:00 51.02 -26.674936 -13.573971 \n",
"2011-12-01 11:15:00+00:00 40.02 -25.978550 -14.721908 \n",
"2011-12-01 11:20:00+00:00 41.11 -26.321925 -14.392925 \n",
"2011-12-01 11:25:00+00:00 39.71 -25.658147 -13.493687 \n",
"2011-12-01 11:30:00+00:00 40.42 -24.929367 -13.288685 \n",
"2011-12-01 11:35:00+00:00 36.69 -21.397070 -9.348150 \n",
"2011-12-01 11:40:00+00:00 44.13 -21.793565 -6.596470 \n",
"2011-12-01 11:45:00+00:00 48.38 -25.216045 -7.646801 \n",
"2011-12-01 11:50:00+00:00 41.94 -24.453287 -3.262765 \n",
"2011-12-01 11:55:00+00:00 37.45 -19.892211 -6.379032 \n",
"2011-12-01 12:00:00+00:00 48.27 -21.896934 -6.171449 \n",
"\n",
"[145 rows x 8 columns]\n"
]
}
],
"source": [
"print(dat['2011-12-01 00:00:00':'2011-12-01 12:00:00'])"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"
\n",
"What if we want to grab data that fall on the *12th hour of every day*?"
]
},
{
"cell_type": "code",
"execution_count": 30,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
" Station_ID air_temp_set_1 relative_humidity_set_1 \\\n",
"Date_Time \n",
"2011-12-01 12:00:00+00:00 WBB 3.111111 36.89 \n",
"2011-12-01 12:05:00+00:00 WBB 3.050000 36.80 \n",
"2011-12-01 12:10:00+00:00 WBB 2.977778 36.28 \n",
"2011-12-01 12:15:00+00:00 WBB 2.877778 36.44 \n",
"2011-12-01 12:20:00+00:00 WBB 2.961111 35.82 \n",
"2011-12-01 12:25:00+00:00 WBB 2.927778 35.96 \n",
"2011-12-01 12:30:00+00:00 WBB 2.922222 35.65 \n",
"2011-12-01 12:35:00+00:00 WBB 3.122222 33.92 \n",
"2011-12-01 12:40:00+00:00 WBB 2.988889 35.06 \n",
"2011-12-01 12:45:00+00:00 WBB 2.777778 35.91 \n",
"2011-12-01 12:50:00+00:00 WBB 2.811111 35.55 \n",
"2011-12-01 12:55:00+00:00 WBB 2.738889 35.83 \n",
"2011-12-02 12:00:00+00:00 WBB -1.738889 50.04 \n",
"2011-12-02 12:05:00+00:00 WBB -1.488889 48.59 \n",
"2011-12-02 12:10:00+00:00 WBB -1.700000 50.37 \n",
"2011-12-02 12:15:00+00:00 WBB -1.922222 51.27 \n",
"2011-12-02 12:20:00+00:00 WBB -2.050000 51.73 \n",
"2011-12-02 12:25:00+00:00 WBB -2.227778 52.03 \n",
"2011-12-02 12:30:00+00:00 WBB -2.388889 51.57 \n",
"2011-12-02 12:35:00+00:00 WBB -2.450000 52.25 \n",
"2011-12-02 12:40:00+00:00 WBB -2.338889 51.95 \n",
"2011-12-02 12:45:00+00:00 WBB -2.161111 50.36 \n",
"2011-12-02 12:50:00+00:00 WBB -1.877778 48.63 \n",
"2011-12-02 12:55:00+00:00 WBB -1.927778 49.01 \n",
"\n",
" wind_speed_set_1 wind_direction_set_1 \\\n",
"Date_Time \n",
"2011-12-01 12:00:00+00:00 22.75 74.26 \n",
"2011-12-01 12:05:00+00:00 16.80 70.98 \n",
"2011-12-01 12:10:00+00:00 20.56 63.14 \n",
"2011-12-01 12:15:00+00:00 18.39 79.99 \n",
"2011-12-01 12:20:00+00:00 23.42 58.35 \n",
"2011-12-01 12:25:00+00:00 18.54 64.19 \n",
"2011-12-01 12:30:00+00:00 22.10 60.78 \n",
"2011-12-01 12:35:00+00:00 26.93 51.69 \n",
"2011-12-01 12:40:00+00:00 23.55 62.64 \n",
"2011-12-01 12:45:00+00:00 26.40 76.26 \n",
"2011-12-01 12:50:00+00:00 31.56 68.76 \n",
"2011-12-01 12:55:00+00:00 27.36 69.73 \n",
"2011-12-02 12:00:00+00:00 3.33 149.60 \n",
"2011-12-02 12:05:00+00:00 2.89 163.30 \n",
"2011-12-02 12:10:00+00:00 3.18 166.70 \n",
"2011-12-02 12:15:00+00:00 2.10 134.80 \n",
"2011-12-02 12:20:00+00:00 0.54 133.60 \n",
"2011-12-02 12:25:00+00:00 3.38 334.60 \n",
"2011-12-02 12:30:00+00:00 3.62 345.70 \n",
"2011-12-02 12:35:00+00:00 3.33 344.10 \n",
"2011-12-02 12:40:00+00:00 2.91 352.90 \n",
"2011-12-02 12:45:00+00:00 2.98 21.97 \n",
"2011-12-02 12:50:00+00:00 3.56 38.88 \n",
"2011-12-02 12:55:00+00:00 2.06 52.18 \n",
"\n",
" wind_gust_set_1 u_wind v_wind \n",
"Date_Time \n",
"2011-12-01 12:00:00+00:00 48.27 -21.896934 -6.171449 \n",
"2011-12-01 12:05:00+00:00 32.93 -15.882802 -5.475089 \n",
"2011-12-01 12:10:00+00:00 41.47 -18.341847 -9.289255 \n",
"2011-12-01 12:15:00+00:00 31.61 -18.110057 -3.196551 \n",
"2011-12-01 12:20:00+00:00 42.61 -19.936728 -12.289153 \n",
"2011-12-01 12:25:00+00:00 29.89 -16.690501 -8.072098 \n",
"2011-12-01 12:30:00+00:00 36.31 -19.287813 -10.788432 \n",
"2011-12-01 12:35:00+00:00 45.81 -21.131114 -16.694338 \n",
"2011-12-01 12:40:00+00:00 44.49 -20.915613 -10.823106 \n",
"2011-12-01 12:45:00+00:00 53.66 -25.644525 -6.270432 \n",
"2011-12-01 12:50:00+00:00 52.86 -29.416164 -11.433411 \n",
"2011-12-01 12:55:00+00:00 48.09 -25.665608 -9.478722 \n",
"2011-12-02 12:00:00+00:00 5.08 -1.685092 2.872171 \n",
"2011-12-02 12:05:00+00:00 4.16 -0.830472 2.768107 \n",
"2011-12-02 12:10:00+00:00 4.43 -0.731558 3.094709 \n",
"2011-12-02 12:15:00+00:00 3.94 -1.490099 1.479732 \n",
"2011-12-02 12:20:00+00:00 1.52 -0.391053 0.372395 \n",
"2011-12-02 12:25:00+00:00 4.94 1.449801 -3.053273 \n",
"2011-12-02 12:30:00+00:00 4.88 0.894136 -3.507837 \n",
"2011-12-02 12:35:00+00:00 4.25 0.912284 -3.202599 \n",
"2011-12-02 12:40:00+00:00 3.94 0.359680 -2.887686 \n",
"2011-12-02 12:45:00+00:00 4.07 -1.114881 -2.763592 \n",
"2011-12-02 12:50:00+00:00 4.00 -2.234581 -2.771326 \n",
"2011-12-02 12:55:00+00:00 3.47 -1.627278 -1.263157 \n"
]
}
],
"source": [
"print(dat[dat.index.hour == 12])"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"
\n",
"And you get the idea..."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"
\n",
"\n",
"# Do it yourself #4\n",
"\n",
"Lets play around with some hourly air quality data from the EPA We are going to read in a very large data set from EPA's AirNow website, which one-stop source for air quality data.Good news is there is a lot of data, especially for the western U.S. The bad news? They give us everything! This data set is an example where programs like Microsoft Excel really start getting bogged down, and therefore requires a different *'tool'*, which in this case, will be \n",
"Python!\n",
"\n",
"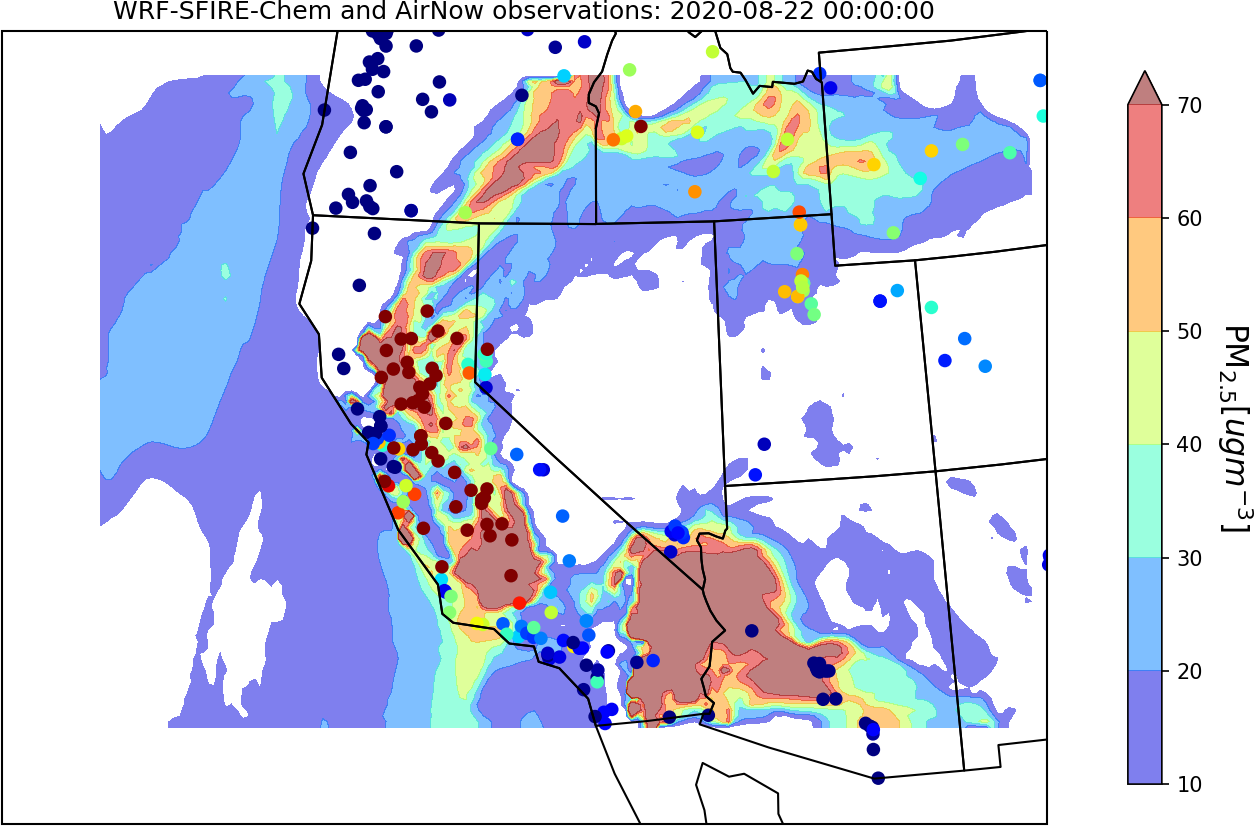 \n",
"\n",
"For this **Do it Yourself**, I want the class to read in this data using pandas read csv function:"
]
},
{
"cell_type": "code",
"execution_count": 31,
"metadata": {},
"outputs": [],
"source": [
"#Set linux path to our file and concatenate the path and string\n",
"filepath = '/uufs/chpc.utah.edu/common/home/u0703457/lin-group7/dvm/projects/UDAQ_2020-22/obs/AirNow/'\n",
"filename = 'hourly_88101_PM25_2020.csv'\n",
"filename = filepath+filename\n",
"\n",
"#Read in data with our pandas read_csv function. Only read in specific columns of this data set as given by\n",
"#the usecols arguement. Rename the column names to something simpler.\n",
"aq_dat = pd.read_csv(filename,sep=\",\",usecols=['State Code','County Code','Site Num','Latitude','Longitude','Date GMT','Time GMT','Sample Measurement'],parse_dates=[['Date GMT', 'Time GMT']])\n",
"aq_dat = aq_dat.rename(columns={'Latitude': 'lat','Longitude':'lon','Date GMT_Time GMT':'Time','Sample Measurement':'pm25'}) "
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"
\n",
"\n",
"For this **Do it Yourself**, I want the class to read in this data using pandas read csv function:"
]
},
{
"cell_type": "code",
"execution_count": 31,
"metadata": {},
"outputs": [],
"source": [
"#Set linux path to our file and concatenate the path and string\n",
"filepath = '/uufs/chpc.utah.edu/common/home/u0703457/lin-group7/dvm/projects/UDAQ_2020-22/obs/AirNow/'\n",
"filename = 'hourly_88101_PM25_2020.csv'\n",
"filename = filepath+filename\n",
"\n",
"#Read in data with our pandas read_csv function. Only read in specific columns of this data set as given by\n",
"#the usecols arguement. Rename the column names to something simpler.\n",
"aq_dat = pd.read_csv(filename,sep=\",\",usecols=['State Code','County Code','Site Num','Latitude','Longitude','Date GMT','Time GMT','Sample Measurement'],parse_dates=[['Date GMT', 'Time GMT']])\n",
"aq_dat = aq_dat.rename(columns={'Latitude': 'lat','Longitude':'lon','Date GMT_Time GMT':'Time','Sample Measurement':'pm25'}) "
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"
\n",
"**Step 1:** How many Sample Measurements (PM2.5) do we have?"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"**Step 2:** Filter the above data set by latitude and longitude. Lets filter out everything west of *-112.5 W*\n",
"and east of *-111.5 W* and north of *41 N* and south of *40 N*\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"**Step 3:** Now, lets filter this by time. Lets only grab data between 2020-08-21 and 2020-08-24. This can be done using the between method, which is super useful when working with pandas time series. For example:
\n",
"`data[data['Time'].between('2020-08-21', '2020-08-24')]`\n",
"
\n",
"**QUESTION! Why didn't we assign the time to the index like the earlier example??**\n",
"
"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"**Step 4:** After we've filtered our data set, how many Sample Measurements (PM2.5) do we have?"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"**Step 5:** What is the highest PM2.5 reading that we have? What is the lowest reading? What is the average PM2.5 reading?"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"**Step 6:** Looking at the data, does anything look odd? If so, how should we handle this?"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"
\n",
"\n",
"# Want more practice!?\n",
"Check out the following webpages:
\n",
"https://pandas.pydata.org/pandas-docs/version/0.15/tutorials.html
\n",
"https://www.youtube.com/watch?v=dcqPhpY7tWk&t=113s
\n",
"https://www.earthdatascience.org/courses/use-data-open-source-python/use-time-series-data-in-python/date-time-types-in-pandas-python/subset-time-series-data-python/
\n",
"\n",
"\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": []
}
],
"metadata": {
"kernelspec": {
"display_name": "Python 3",
"language": "python",
"name": "python3"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.6.7"
}
},
"nbformat": 4,
"nbformat_minor": 4
}